5 Segmentation
Segmenting customers well is genuinely difficult. Finding patterns in business data is easy; finding patterns you can act on is not. Many patterns only describe the structure of a market, such as who happens to live where or who happens to be older, rather than a difference you can exploit. On top of that, a sports club rarely has the scale or the data depth of a Facebook, a Google, or even its own league. Without partnerships, you cannot approach segmentation the way those companies do. That is the reality you work within.
This chapter has two parts:
- Preparing the data for analysis
- Analyzing and interpreting the results
It is also where the book shifts to fuller worked examples. From here on, we walk through complete analyses, including the code, output, and interpretation, using the simulated data from Chapter 2. Before starting a project like this, ask yourself four questions:
- What am I trying to accomplish?
- How will the output be used?
- Who will use it?
- What is the incremental value of the work?
The fourth question matters most, because your time is limited. Segmentation can use many machine-learning techniques, and we will cover a few of the most useful, but none of them guarantees a result. You may find nothing, for any of several reasons: the data is bad, there is not enough of it, the technique is wrong, the problem was framed poorly, or there simply is nothing there.
A consultant always finds something because they have to. Working inside a club, you should hold a different standard:
The worst outcome of an analytics project is to believe you found something, deploy it, and be wrong.
A false segment does not just waste effort. It can actively harm the organization and erode the credibility of analytics. It is fine to come up empty. First, do no harm.
5.1 Building a segmentation scheme
Our example combines demographic data with stated preferences from a survey. The goal is a simple scheme that does a reasonable job of explaining who buys tickets and why. We group on demographics for discoverability, but what we are really hunting for is a difference in behavior. For the project to be worthwhile, four things have to hold:
- We must tell segments apart from market structure. Groups that do not differ in behavior are not useful segments.
- We must be able to reach each segment selectively, through a product or a channel.
- We must be willing to keep experimenting, because segments have to be validated over time.
- Sales and marketing leadership has to stay involved.
A segment can fail by being too broad or by being irrelevant. “People with brown eyes” is both. The aim is to find groups of fans who differ in ways that connect to how we communicate, what content they want, and how they respond to marketing. Put simply: who is our customer, and what do they want?
The analysis has two components that we will eventually overlay:
- A demographic segmentation built from third-party data.
- A set of behavioral archetypes built from survey responses.
Segmentation is never finished and is never a magic bullet. For a club the constraints are real: you do not have unlimited scale, and your samples are relatively small. You cannot run continuous experiments the way a large platform does. These projects tend to be more useful for helping marketers understand the structure of the fan base and make small, compounding improvements across campaigns. Judge success by whether the work produces testable hypotheses that let you change the behavior of a segment through better measurement of marketing return, higher conversion, or sharper product offers.
5.2 Demographic segmentation
Demographic segmentation is attractive mostly because it is discoverable: you can find these people again. It is also easy to overrate. Steve Koonin, then CEO of the Atlanta Hawks, famously dismissed the “Alpharetta unicorn”:
“The 55-year-old guy who’s going to drive an hour from Alpharetta into the city with three buddies to go to the Hawks game. He doesn’t exist. And there is no music, no kiss cam, no cheerleaders … nothing is going to change that.”
— Steve Koonin 25
Alpharetta is an affluent, less diverse, geographically isolated suburb of Atlanta. Koonin’s point was that the Hawks’ brand was not congruent with the marketing aimed at that imagined fan. Maybe the segment does not exist; maybe it just was not relevant to his situation. Either way, the lesson holds: a demographic group is only a segment if it behaves like one.
Our sample lives in the FOSBAAS package as demographic_data.
library(FOSBAAS)
demo_data <- FOSBAAS::demographic_dataThe table has 200,000 rows and 14 columns of standard demographic attributes. Latitude and longitude have already been turned into a distance metric. We will keep the columns that look useful for segmentation.
demo_data <- demo_data |>
dplyr::select(custID, ethnicity, age, maritalStatus,
children, hhIncome, distance, gender)| variable | class | first_values |
|---|---|---|
| custID | character | MBT9G0X70NTI, QTR3JJJ5J6GJ |
| ethnicity | character | w, w |
| age | numeric | 55, 30 |
| maritalStatus | character | m, s |
| children | character | y, n |
| hhIncome | numeric | 2866, 552 |
| distance | numeric | 48.34, 77.09 |
| gender | character | m, f |
We have a mix of discrete fields (ethnicity, marital status) and continuous ones (age, distance, household income). That mix matters, because it shapes how we process the data and which algorithms we can use. hhIncome is a modeled index rather than a dollar figure, which is common in purchased data. You would need a data dictionary to know exactly what the numbers mean; here, larger is higher.
5.2.1 Exploring the demographic data
We start the same way as Chapter 3: one variable at a time. A histogram of age, split by gender, is a good first look.
ggplot(demo_data, aes(x = age, fill = gender)) +
geom_histogram(binwidth = 2, color = "white") +
scale_fill_manual("Gender", values = plot_palette) +
scale_y_continuous(labels = scales::comma) +
labs(x = "Age", y = "Count", title = "Age has more than one peak") +
book_theme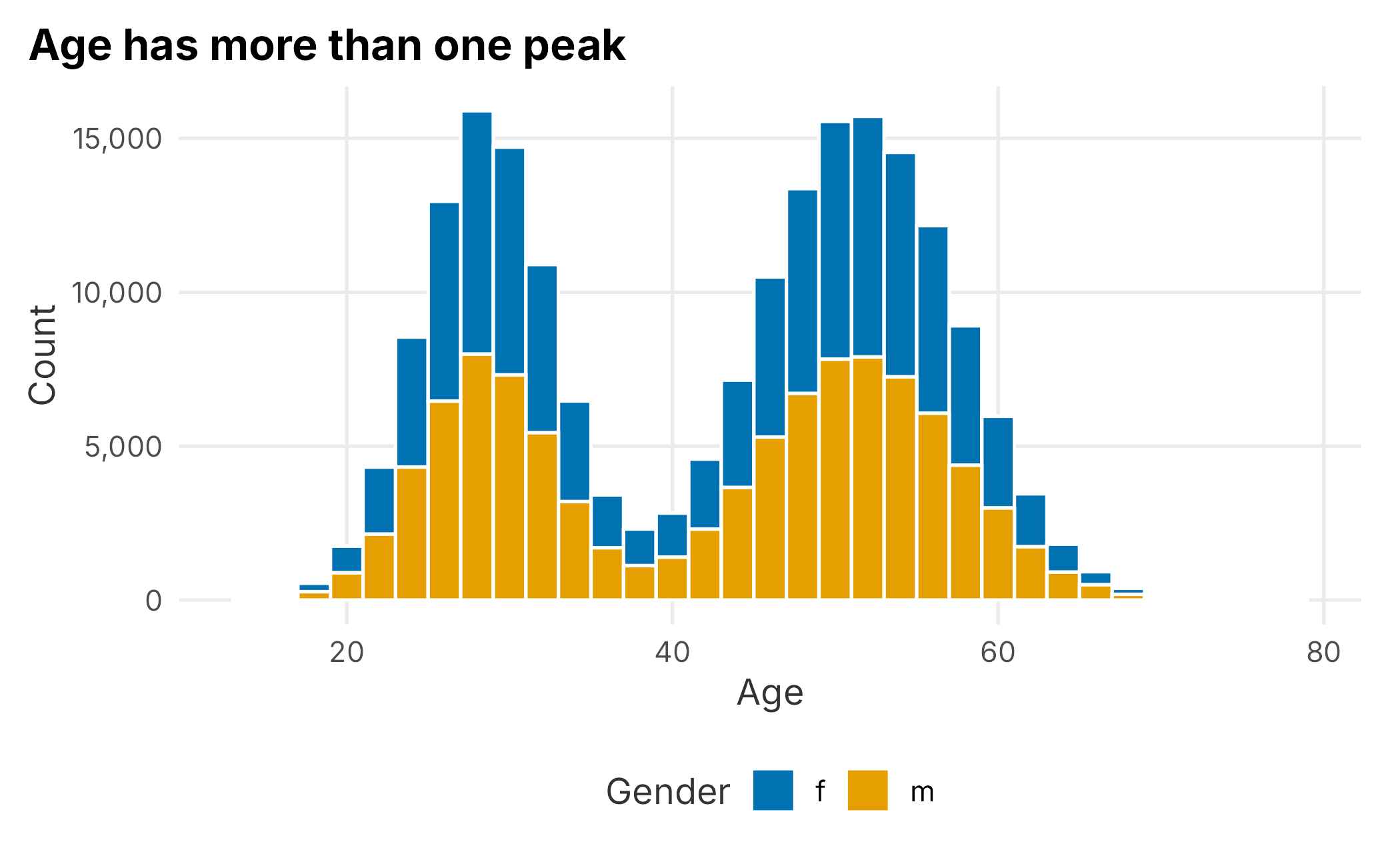
Figure 5.1: Distribution of customer age
The distribution is not a simple bell shape; it has more than one peak. That already tells us an “average age” would be misleading. Splitting by gender shows men and women are distributed almost identically, so gender is not doing much work on its own here.
Distance is the next continuous field, and it behaves very differently.
ggplot(demo_data, aes(x = distance)) +
geom_histogram(binwidth = 10, fill = plot_palette[1], color = "white") +
scale_x_continuous(labels = scales::comma) +
scale_y_continuous(labels = scales::comma) +
labs(x = "Distance", y = "Count", title = "Distance has a long right tail") +
book_theme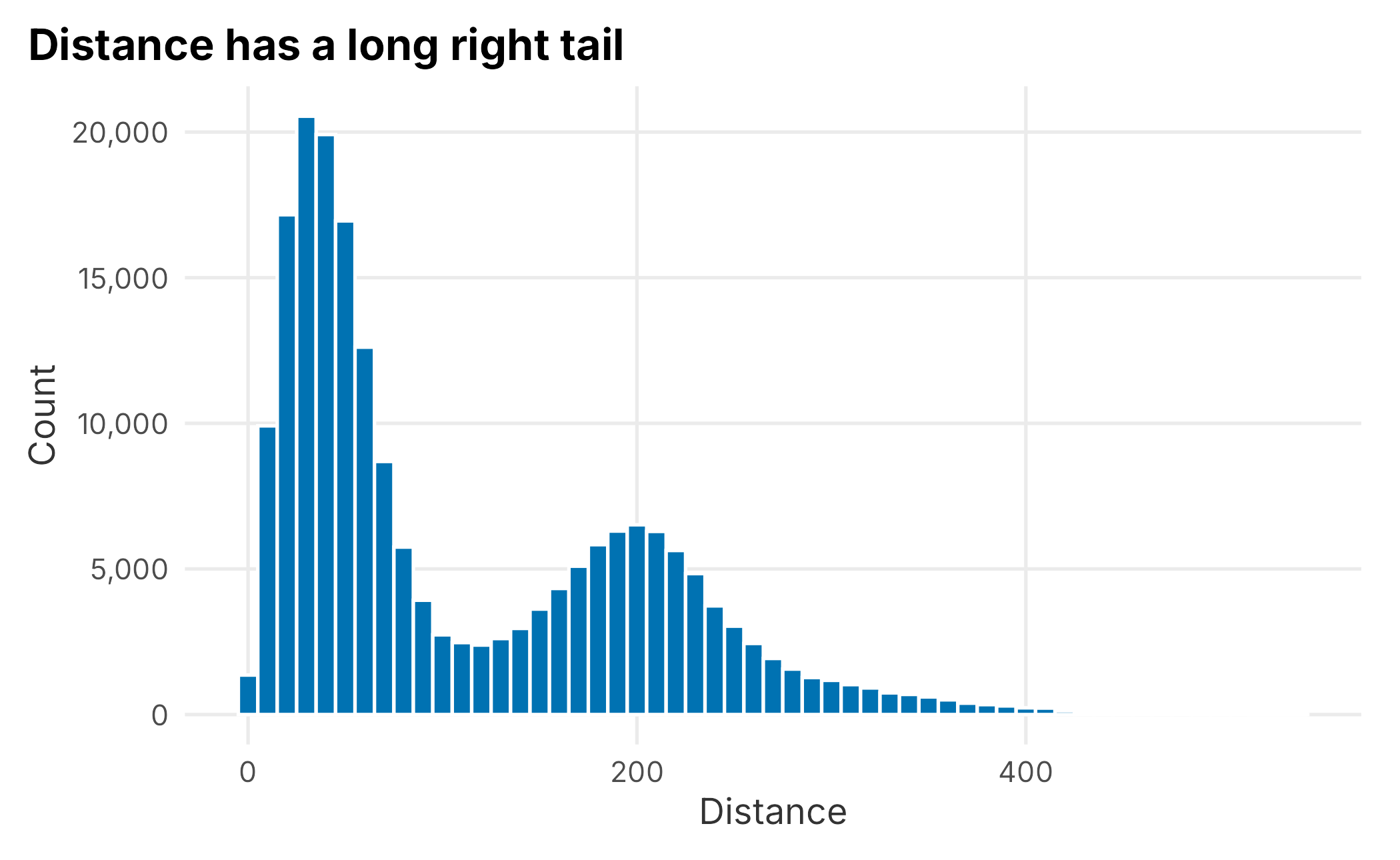
Figure 5.2: Distribution of distance from the ballpark
Distance is heavily right-skewed: the median is about 66 miles while the mean is over 110. When the mean sits well above the median, a long right tail is pulling it up. A small number of customers live very far away. That skew can cause problems for some models, but it is useful for understanding market structure: it is simply easier for nearby people to buy and attend, and season-ticket holders tend to live closer. Be careful how you define distance, though. Whose distance are you measuring: the buyer, each ticket user, or a company account?
Household income is also continuous and, being modeled, has several peaks.
ggplot(demo_data, aes(x = hhIncome)) +
geom_histogram(bins = 40, fill = plot_palette[1], color = "white") +
scale_x_continuous(labels = scales::comma) +
scale_y_continuous(labels = scales::comma) +
labs(x = "Household income index", y = "Count",
title = "A modeled income index tends to cluster") +
book_theme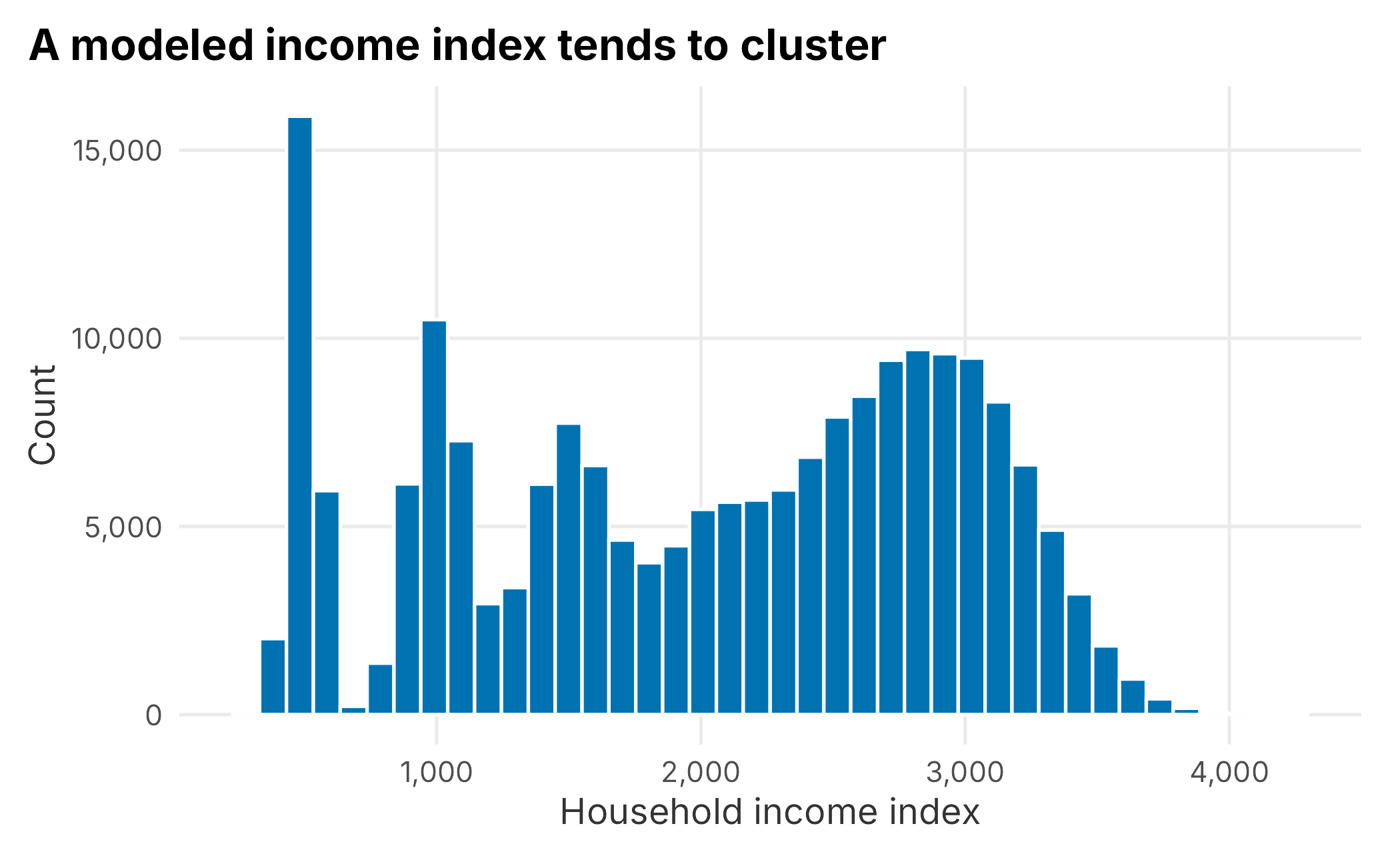
Figure 5.3: Distribution of household income index
It is worth pausing here. We are looking for differences in behavior tied to a discoverable group. We do not yet have a reason to believe income changes how someone behaves as a fan. Higher income does not always mean more disposable income. People tend to spend up to their means, and a bigger house represents wealth rather than necessarily indicating spending money. Hold the question loosely until the data answers it.
A single grouped summary is tidier than three separate describe calls.
| variable | mean | median | sd |
|---|---|---|---|
| age | 42.8 | 46.0 | 12.5 |
| distance | 110.1 | 66.5 | 92.1 |
| hhIncome | 2020.1 | 2153.0 | 925.7 |
As a rule, do not compute the same thing five different ways. If you can imagine a view of your data, someone has probably already solved it.
5.2.1.1 Categorical variables
For categorical fields, a proportion table shows how large each group is. Ethnicity is the clearest example.
| ethnicity | n | proportion |
|---|---|---|
| a | 4719 | 0.024 |
| aa | 20805 | 0.104 |
| h | 14265 | 0.071 |
| w | 160211 | 0.801 |
White fans make up about 80% of the sample, with the remaining 20% split across the other groups. Analyzing ethnicity is fraught. It is a loaded topic, and it is easy for an analyst to make things worse because prior expectations can shape the patterns you think you see. As a point estimate it may mean very little. Longitudinally it can matter: if ticket buyers cluster near the park and lean toward one group today, what happens as the area’s population changes over ten years?
Ethnicity, gender, age, and similar fields also require governance beyond model fit. A field may be useful for diagnosing representation or auditing outcomes without being appropriate for campaign targeting, differential pricing, or exclusion. Before activating any segment built from sensitive attributes, document the business purpose, review applicable policy and law, restrict access, and test whether the resulting treatment is fair.
A grouped summary lets us check whether the numeric attributes differ much by ethnicity.
demo_data |>
group_by(ethnicity) |>
summarise(
n = n(),
mean_age = mean(age),
mean_distance = mean(distance),
mean_income = mean(hhIncome),
.groups = "drop"
)## # A tibble: 4 × 5
## ethnicity n mean_age mean_distance mean_income
## <chr> <int> <dbl> <dbl> <dbl>
## 1 a 4719 42.2 111. 1995.
## 2 aa 20805 44.4 119. 2089.
## 3 h 14265 43.0 108. 2029.
## 4 w 160211 42.6 109. 2011.The groups are broadly similar. The largest difference is simply how many more white fans there are. Whether that is congruent with the local population is a question worth asking, but the behavioral attributes do not separate sharply on ethnicity alone. Never skip looking at each field individually. Understanding the structure now saves grief later.
5.2.2 Preparing the data for modeling
You will spend more time preparing data than analyzing it. The two problems you will hit most often are missing data and sparse data. Missing data is the larger headache, and it is worth a careful look.
A small helper counts the usual culprits.
f_missing_data <- function(df) {
data.frame(
NA_count = sum(vapply(df, function(x) sum(is.na(x)), numeric(1))),
NaN_count = sum(vapply(df, function(x) sum(is.nan(x)), numeric(1))),
Inf_count = sum(vapply(df, function(x) sum(is.infinite(x)), numeric(1)))
)
}
f_missing_data(demo_data)## NA_count NaN_count Inf_count
## 1 0 0 0Nothing is missing, which is no surprise because the data is simulated. To make the example real, we will knock out about 2% of the values at random, column by column, so each field keeps its type.
set.seed(755)
demo_data <- demo_data |>
mutate(across(everything(), function(col) {
col[runif(length(col)) > 0.98] <- NA
col
}))
f_missing_data(demo_data)## NA_count NaN_count Inf_count
## 1 32211 0 0About 4,000 values are now missing in each column. Because the missing cells are spread across columns, the rows they fall in often differ, so deleting every row with any missing value would cost more than 2%.
complete_rows <- sum(complete.cases(demo_data))
data.frame(
total_rows = nrow(demo_data),
complete_rows = complete_rows,
incomplete_rows = nrow(demo_data) - complete_rows
)## total_rows complete_rows incomplete_rows
## 1 200000 169903 30097Roughly 30,000 rows have at least one missing value. The remaining ~170,000 rows sound ample, but sample size alone does not make a data set representative. Adequacy depends on the smallest segments, the strength of the patterns, why values are missing, and how the model performs on validation data. Deleting incomplete rows can still bias a large data set if missingness is systematic.
Now we impute. The key question is always why the data is missing. If it is missing for a systematic reason, such as a long survey that people abandon, the missingness itself can bias your results. That is the technical idea behind data that is “not missing at random.” Our data is missing at random by construction, so we can be pragmatic.
For the categorical fields and age, we use a simple stochastic hot-deck approach: each missing value is sampled from the observed values in that field. This preserves each marginal distribution better than filling every gap with the mode or mean, though it does not preserve relationships among fields.
sample_observed <- function(x) {
missing <- is.na(x)
x[missing] <- sample(x[!missing], sum(missing), replace = TRUE)
x
}
set.seed(755)
demo_data$ethnicity <- sample_observed(demo_data$ethnicity)Age is multimodal, so a single mean or median would create an artificial spike. Sampling observed ages preserves the shape of the distribution.
demo_data$age <- sample_observed(demo_data$age)This simple fill is defensible only because the missingness is both light and random by construction. With real data, compare the imputed and observed distributions and test whether the segmentation changes under reasonable alternative methods.
We apply the same observed-distribution approach to marital status, children, and gender. The probabilities come from the data rather than hard-coded assumptions.
demo_data <- demo_data |>
mutate(across(c(maritalStatus, children, gender), sample_observed))For the two remaining numeric fields, income and distance, we can use mice (van Buuren and Groothuis-Oudshoorn 2025). It offers more than a dozen methods; we use predictive mean matching (pmm). Multiple imputation is normally used to propagate uncertainty through statistical inference. Clustering does not have an equally simple pooling rule, so this demonstration uses one completed data set. In production, repeat the segmentation across several completed data sets and treat agreement as another stability check.
library(mice)
imp_frame <- demo_data |> dplyr::select(hhIncome, distance)
imputed <- mice(imp_frame, m = 5, maxit = 10, method = "pmm",
seed = 755, printFlag = FALSE)
completed <- complete(imputed, 1)
demo_data$hhIncome <- completed$hhIncome
demo_data$distance <- completed$distanceFinally, where the customer ID itself is missing we just drop the row because without an ID we cannot tie the demographics back to behavior, which is the whole point.
demo_data <- na.omit(demo_data)
f_missing_data(demo_data)## NA_count NaN_count Inf_count
## 1 0 0 0No more missing values. You are not an imputation expert now, but you have the gist: it is tedious, judgment-heavy work with no single right answer. If 40% of your data were missing, you would think much harder about why before patching it. The point is to keep the goal in mind while you do it.
5.2.3 Discretizing the numeric variables
Some methods, including the latent class regression we use shortly, require discrete inputs. Turning continuous fields into categories is part art. We will do it three ways.
For age, we map birth year to a familiar generation. We anchor to a fixed reference year so the assignments are reproducible and do not drift as the calendar advances.
reference_year <- 2024
f_generation <- function(birth_year) {
if (birth_year <= 1945) "gen_Silent"
else if (birth_year <= 1964) "gen_Boomer"
else if (birth_year <= 1979) "gen_X"
else if (birth_year <= 1994) "gen_Mill"
else "gen_Z"
}
generation <- vapply(reference_year - demo_data$age, f_generation, character(1))Programmers love to criticize a chain of if/else like this; there are tidier constructs. For a readable, one-time transformation on data this size, it is fine. Storing birth year rather than age also keeps the data evergreen. That is worth remembering when you design a survey.
For distance, we cut on quantiles into four market rings.
dist_q <- quantile(demo_data$distance, probs = c(.25, .50, .75))
f_market <- function(d) {
if (d <= dist_q[[1]]) "dist_Primary"
else if (d <= dist_q[[2]]) "dist_Secondary"
else if (d <= dist_q[[3]]) "dist_Tertiary"
else "dist_Quaternary"
}
market_loc <- vapply(demo_data$distance, f_market, character(1))Income gets three buckets, low/medium/high, split at the quartiles. More categories mean more columns later, so keep the count modest.
inc_q <- quantile(demo_data$hhIncome, probs = c(.25, .75))
f_income <- function(v) {
if (v <= inc_q[[1]]) "income_low"
else if (v >= inc_q[[2]]) "income_high"
else "income_med"
}
income_band <- vapply(demo_data$hhIncome, f_income, character(1))We assemble these into a discrete table keyed by customer.
demo_data_discrete <- data.frame(
custID = demo_data$custID,
generation = generation,
marketLoc = market_loc,
income = income_band,
ethnicity = demo_data$ethnicity,
married = demo_data$maritalStatus,
gender = demo_data$gender
)| custID | generation | marketLoc | income | ethnicity | married | gender |
|---|---|---|---|---|---|---|
| MBT9G0X70NTI | gen_X | dist_Secondary | income_high | w | m | m |
| HOMV3XQW32LW | gen_Mill | dist_Secondary | income_med | w | s | f |
| RJ7CCATUH4Q1 | gen_Z | dist_Secondary | income_med | w | s | f |
| 9GZT5Z5AOMKV | gen_X | dist_Primary | income_med | w | m | m |
| S0Y0Y2454IU2 | gen_X | dist_Tertiary | income_high | w | m | m |
| YOZ51B6A2QMB | gen_Z | dist_Primary | income_med | h | s | m |
5.2.3.1 Dummy coding
Many models need each category expanded into its own 0/1 column. psych::dummy.code does this, and applying it column by column gives us prefixed names like generation.gen_X, which keeps otherwise-colliding levels (marital m and gender m) distinct.
dummy_list <- lapply(
demo_data_discrete[, 2:7],
function(x) psych::dummy.code(factor(x))
)
mod_data_discrete <- do.call(cbind.data.frame, dummy_list)
row.names(mod_data_discrete) <- demo_data_discrete$custID| generation.gen_X | generation.gen_Mill | generation.gen_Z | generation.gen_Boomer | generation.gen_Silent | |
|---|---|---|---|---|---|
| MBT9G0X70NTI | 1 | 0 | 0 | 0 | 0 |
| HOMV3XQW32LW | 0 | 1 | 0 | 0 | 0 |
| RJ7CCATUH4Q1 | 0 | 0 | 1 | 0 | 0 |
| 9GZT5Z5AOMKV | 1 | 0 | 0 | 0 | 0 |
| S0Y0Y2454IU2 | 1 | 0 | 0 | 0 | 0 |
| YOZ51B6A2QMB | 0 | 0 | 1 | 0 | 0 |
For methods that accept a mix of numeric and binary inputs, we also build a frame that keeps the raw numeric fields and adds the ethnicity, marital, and gender dummies. Selecting by name prefix is safer than selecting by column position.
cat_dummies <- mod_data_discrete |>
dplyr::select(starts_with(c("ethnicity.", "married.", "gender.")))
mod_data_numeric <- cbind.data.frame(
demo_data[, c("age", "distance", "hhIncome")],
cat_dummies
)
mod_data_numeric$age <- as.numeric(mod_data_numeric$age)| age | distance | hhIncome | ethnicity.w | ethnicity.aa | |
|---|---|---|---|---|---|
| MBT9G0X70NTI | 55 | 48.34 | 2866 | 1 | 0 |
| HOMV3XQW32LW | 30 | 46.72 | 2274 | 1 | 0 |
| RJ7CCATUH4Q1 | 29 | 65.45 | 1773 | 1 | 0 |
| 9GZT5Z5AOMKV | 48 | 19.28 | 1951 | 1 | 0 |
| S0Y0Y2454IU2 | 49 | 69.20 | 3244 | 1 | 0 |
| YOZ51B6A2QMB | 28 | 31.13 | 1638 | 0 | 0 |
Every column is numeric, which makes this frame consumable by a wide range of tools.
5.2.4 Hierarchical clustering
Hierarchical clustering is appealing because its results draw so nicely. The catch is that for simple inputs it often just confirms what you already know, and it scales badly: the dissimilarity matrix grows with the square of the number of rows. That is why we sample. Most “big data” problems are small data problems in disguise. Here we use 25 people.
library(cluster)
set.seed(755)
hc_sample <- mod_data_numeric |> dplyr::sample_n(25)
hc_dist <- cluster::daisy(hc_sample)We cluster the dissimilarity matrix and plot the result.
hc_model <- stats::hclust(hc_dist, method = "centroid")
plot(hc_model, main = "", xlab = "", sub = "")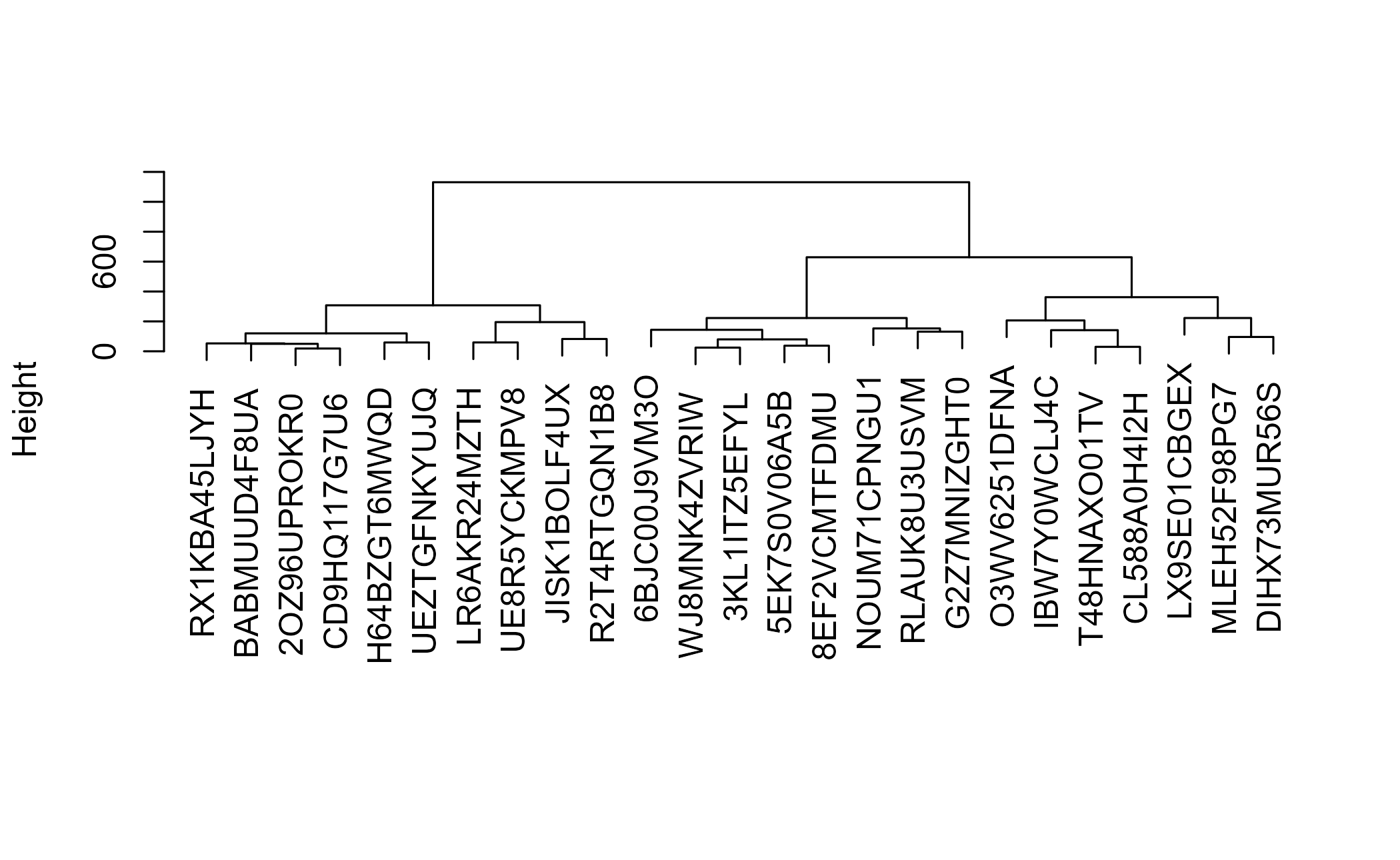
Figure 5.4: Hierarchical clustering dendrogram
You can see fans grouping together, but the cuts tend to fall in predictable places because so much of the data is categorical. It is a useful picture, not a durable segmentation.
5.2.5 Latent class analysis
Latent class analysis models the joint distribution of discrete variables. Unlike the hierarchical example, it should use each original categorical field once. Feeding it every dummy column would duplicate the same information, create deterministic dependencies, and give variables with more levels extra weight. The poLCA function expects categories coded as positive integers, so we encode each field and preserve the customer IDs as row names.
lc_ids <- demo_data_discrete$custID
mod_data_LC <- demo_data_discrete |>
dplyr::select(-custID) |>
dplyr::mutate(across(everything(), ~ as.integer(factor(.x))))
row.names(mod_data_LC) <- lc_idsThe formula includes the six categorical measurements. The right side is 1 because this is a latent class model without covariates; adding predictors there would turn it into a latent class regression.
lc_formula <- cbind(
generation, marketLoc, income, ethnicity, married, gender
) ~ 1We ask for five classes to keep the worked example comparable and interpretable. A production analysis should fit several class counts, compare information criteria such as BIC, inspect class sizes, and verify that the chosen solution is stable. Mixture models can settle on local optima. We use one seeded start to keep the book build practical, but a production analysis should use many random starts and retain the best fit.
library(poLCA)
set.seed(363)
seg_lcr <- poLCA::poLCA(
lc_formula, data = mod_data_LC, nclass = 5,
nrep = 1, maxiter = 2000, verbose = FALSE
)You can save a fitted model to reuse on new data later.
save(seg_lcr, file = "CH5_LCR_5_Model.Rdata")The classes are far from equal in size.
| class | members |
|---|---|
| 1 | 64821 |
| 2 | 4509 |
| 3 | 81725 |
| 4 | 28677 |
| 5 | 16295 |
The smallest class has about 4,500 people; the largest about 81,700. We attach the class back to each customer and join it to the demographic table.
mod_results <- data.frame(
custID = row.names(mod_data_LC),
lcrClass = seg_lcr$predclass
)
demo_data_segments <- demo_data |>
dplyr::left_join(mod_results, by = "custID")
demo_data_segments$age <- as.numeric(demo_data_segments$age)Now we can cross-tabulate to see what actually separates the classes. Start with distance.
| lcrClass | mean_distance | median_distance |
|---|---|---|
| 1 | 109.3 | 66.1 |
| 2 | 144.1 | 65.5 |
| 3 | 103.6 | 47.5 |
| 4 | 125.1 | 126.5 |
| 5 | 109.1 | 65.6 |
Distance now distinguishes some of the classes. Mean distance ranges from about 104 to 144 miles, while median distance ranges from about 48 to 127. The gap between means and medians also shows why a single summary is inadequate for this skewed field.
| lcrClass | mean_age | median_age |
|---|---|---|
| 1 | 28.7 | 28 |
| 2 | 51.6 | 52 |
| 3 | 52.2 | 52 |
| 4 | 52.1 | 52 |
| 5 | 32.6 | 32 |
Age falls into three broad tiers: roughly 29, 33, and 52. Income mostly tracks age, although the younger classes differ sharply from each other.
| lcrClass | mean_income | median_income |
|---|---|---|
| 1 | 1206 | 1043 |
| 2 | 2439 | 2658 |
| 3 | 2426 | 2632 |
| 4 | 2428 | 2634 |
| 5 | 2383 | 2436 |
Four classes are roughly balanced by gender. The fifth is strongly male-skewed, with about nine men for every woman.
| lcrClass | f | m |
|---|---|---|
| 1 | 39166 | 25655 |
| 2 | 2241 | 2268 |
| 3 | 40735 | 40990 |
| 4 | 14231 | 14446 |
| 5 | 1523 | 14772 |
Ethnicity is more involved, so a heat map reads better than a table. We plot the within-class share rather than raw counts; otherwise the largest latent classes would appear most important simply because they contain more people.
seg_ethnicity <- demo_data_segments |>
count(lcrClass, ethnicity) |>
group_by(lcrClass) |>
mutate(share = n / sum(n)) |>
ungroup()
ggplot(seg_ethnicity, aes(x = ethnicity, y = factor(lcrClass), fill = share)) +
geom_tile(color = "white") +
scale_fill_gradient("Within-class share", low = "#f2f2f2",
high = plot_palette[1], labels = scales::percent) +
labs(x = "Ethnicity", y = "Class",
title = "Ethnicity composition varies across latent classes") +
book_theme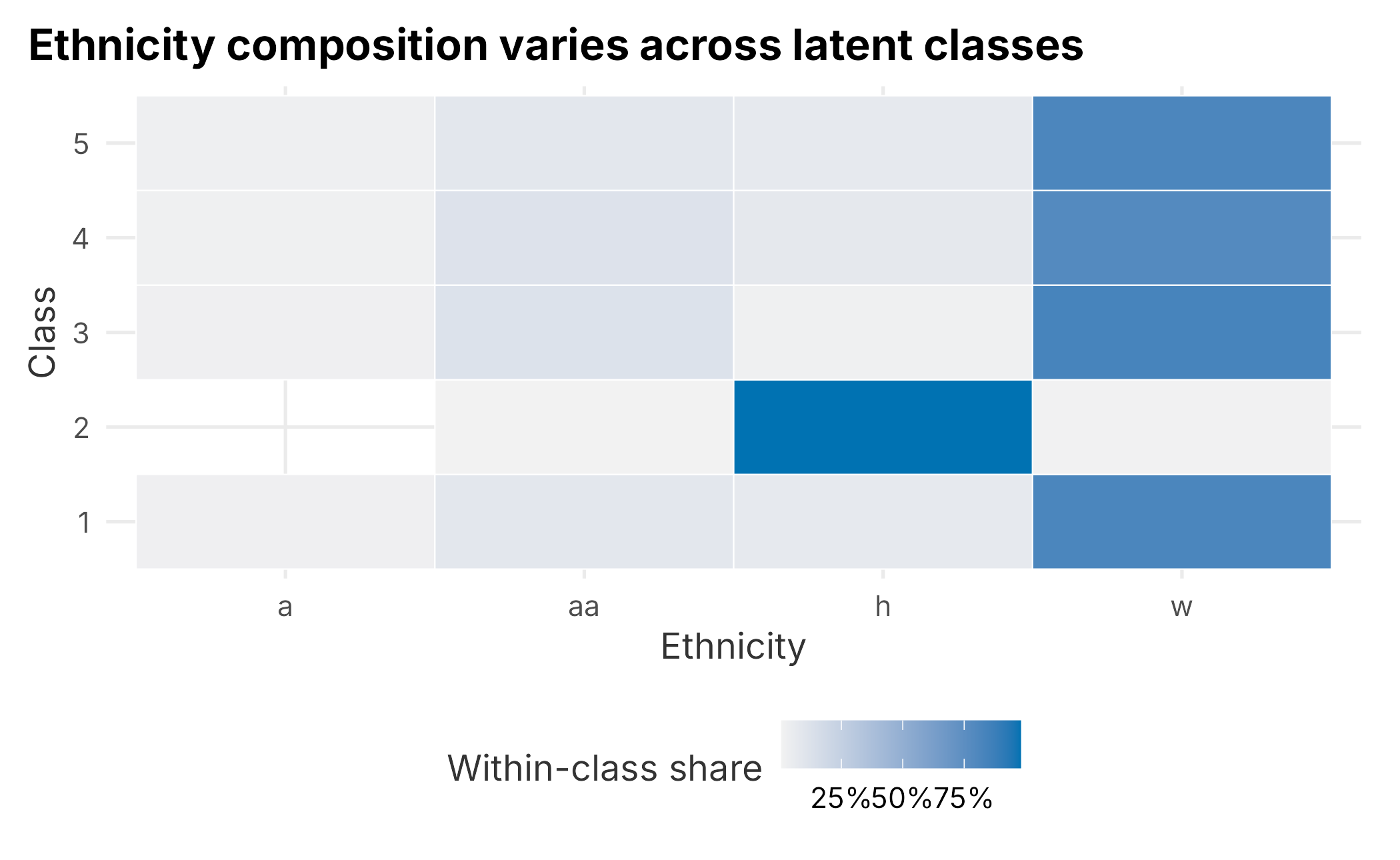
Figure 5.5: Ethnicity by latent class
The classes differ most clearly on age, income, distance, and the male skew in one class. Ethnicity adds composition detail but does not justify targeting on its own. Are these segments or just market structure? We do not know yet. Do they spend differently? Respond to marketing differently? Those questions come next. A common move is to segment on measurable behavior and then look for demographic look-alikes, which is exactly what the rest of the chapter does.
5.3 A benefits-sought approach to segmentation
Behavioral segmentation groups people by what they want. A benefits-sought approach groups fans by what they come to the ballpark to do and gives sharp guidance on how to position an offer. The trade-off is discoverability: it is harder to find these people in a database than it is to find a 40-year-old who lives ten miles away.
We will build the behavioral scheme in three deliberate steps, each answering a different question:
- Exploratory factor analysis (EFA): What underlying tastes does the survey measure? It compresses many stated behaviors into a few archetypes and lets the data suggest how many there are.
- Confirmatory factor analysis (CFA): Does the structure we think we found actually hold up? We write down the model explicitly and test its fit.
- A model-based mixture (GMM): Given those tastes, do fans fall into distinct groups? We cluster fans in the space of their factor scores.
This is more machinery than the demographic side, and it is worth being honest up front about why. Each step is a chance to be wrong, and the last step, turning a smooth cloud of preferences into a handful of named personas, is where analysts most often fool themselves. We will end by asking whether the personas are real enough to act on.
5.3.1 Compressing the survey with factor analysis
Factor analysis is a data-reduction technique, related to principal components analysis. We use it to compress many stated behaviors into a few underlying archetypes. The survey lives in FOSBAAS as fa_survey_data.
survey <- FOSBAAS::fa_survey_data| ReasonForAttending | Socialize | Tailgate | TakeSelfies | PostToSocialMedia |
|---|---|---|---|---|
| Special Game | 2 | 3 | 4 | 2 |
| Support the Team | 4 | 1 | 4 | 0 |
| Celebrate a birthday | 9 | 1 | 4 | 2 |
| Visit the park | 8 | 0 | 0 | 2 |
| Celebrate an anniversary | 0 | 2 | 3 | 2 |
| Company outing | 4 | 2 | 6 | 0 |
Respondents rated a list of 25 ballpark activities from 0 to 10 and gave a reason for attending. The data was not built around specific people, so we will attach customer IDs later to simulate that. We scale the numeric columns and then split respondents into discovery and validation samples. EFA discovers the structure in one half; CFA tests that structure on people who did not help create it.
survey_sc <- as.data.frame(scale(survey[, 2:26]))
set.seed(755)
efa_rows <- sample(seq_len(nrow(survey_sc)), floor(0.50 * nrow(survey_sc)))
survey_efa <- survey_sc[efa_rows, ]
survey_cfa <- survey_sc[-efa_rows, ]How many factors should we extract? A common mistake is to pick a number because it is tidy. Parallel analysis answers the question properly: it compares the structure in your data against the structure you would see in pure noise of the same size, and keeps only the factors that beat noise. The psych package (Revelle 2025) runs it.
set.seed(755)
parallel <- psych::fa.parallel(survey_efa, fm = "ml", fa = "fa", plot = FALSE)| metric | value |
|---|---|
| Suggested factors (parallel analysis) | 3 |
Parallel analysis suggests three factors. This is a useful discipline. The temptation is always to extract more because five factors feel richer than three, but the extra factors are usually noise dressed up as insight. We fit three factors with an oblique rotation (oblimin, from GPArotation (Bernaards et al. 2025)), which lets the factors correlate, as real tastes do.
library(GPArotation)
survey_fa <- psych::fa(survey_efa, nfactors = 3,
rotate = "oblimin", fm = "ml", scores = "regression")To see which activities load on which factor, we reshape the loadings into long form.
loadings <- as.data.frame(unclass(survey_fa$loadings))
loadings$activity <- row.names(loadings)
loadings_long <- loadings |>
tidyr::pivot_longer(!activity, names_to = "factor", values_to = "loading")
ggplot(loadings_long,
aes(x = factor, y = reorder(activity, loading, sum), fill = loading)) +
geom_tile(color = "white") +
geom_text(aes(label = round(loading, 1)), size = 2.6, color = "grey30") +
scale_fill_gradient(low = "white", high = plot_palette[1]) +
labs(x = "Factor", y = "Activity",
title = "Activities cluster onto three underlying factors") +
book_theme +
theme(legend.position = "none")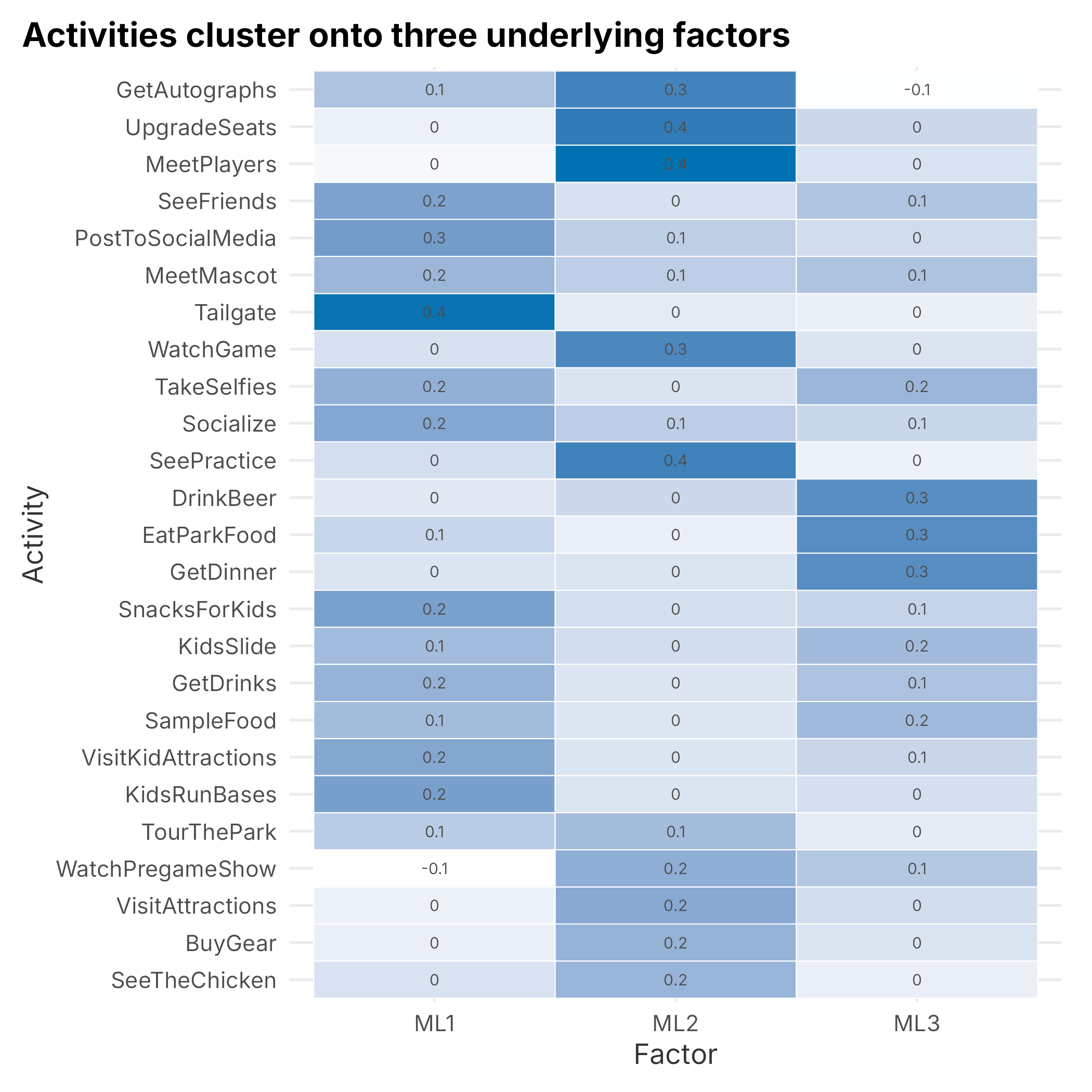
Figure 5.6: Factor loadings by activity
Naming factors is an art, but three groupings fall out cleanly:
- Avid fans: activities centered on the game itself: watching the game, meeting players, getting autographs, upgrading seats, watching practice.
- Socializers: the social and family side: tailgating, posting to social media, taking selfies, seeing friends, and the kids’ activities.
- Foodies: eating and drinking: dinner, park food, sampling, drinks, beer.
Notice what is not here. The old temptation to force five factors invented two extra archetypes, a vague “Parkies” and a catch-all “Strangers,” that carried almost no signal. Parallel analysis spared us that. The loadings here are also modest (mostly 0.2 to 0.4), which is a warning we should keep in mind: the tastes are real but not sharp, and weak structure is exactly the kind that produces fragile segments later.
5.3.2 Confirming the structure with a CFA
The factor analysis above is exploratory: we let the discovery sample decide which activities group together. A confirmatory factor analysis turns the logic around. We write down the structure we believe, with Avid, Socializer, and Foodie factors measured by specific activities, and test how well it reproduces the correlations in the held-out validation sample. It is the difference between “what patterns are in here?” and “does the pattern I claim is here actually hold for new respondents?” lavaan (Rosseel et al. 2025) is the standard tool.
We assign each activity to the factor it loaded on most strongly.
avid <- c("WatchGame", "MeetPlayers", "GetAutographs", "UpgradeSeats",
"SeePractice", "WatchPregameShow", "VisitAttractions",
"BuyGear", "TourThePark", "SeeTheChicken")
social <- c("Socialize", "Tailgate", "PostToSocialMedia", "TakeSelfies",
"SeeFriends", "KidsRunBases", "VisitKidAttractions",
"MeetMascot", "SnacksForKids", "KidsSlide")
food <- c("GetDinner", "EatParkFood", "SampleFood", "GetDrinks", "DrinkBeer")
cfa_model <- paste(
paste("Avid =~", paste(avid, collapse = " + ")),
paste("Social =~", paste(social, collapse = " + ")),
paste("Food =~", paste(food, collapse = " + ")),
sep = "\n"
)The =~ operator reads “is measured by.” We fit the model with std.lv = TRUE so the factors are on a standard scale, and use the robust MLR estimator, which does not lean on the assumption that the ratings are perfectly normal.
cfa_fit <- lavaan::cfa(cfa_model, data = survey_cfa,
std.lv = TRUE, estimator = "MLR")The point of a CFA is the fit indices, a handful of numbers that summarize how well the claimed structure matches the data. CFI and TLI near or above 0.95, RMSEA near or below 0.06, and SRMR near or below 0.08 are common guidelines, not universal pass/fail rules. Fit must be judged alongside sample size, residuals, parameter plausibility, and the model’s intended use.
| index | value |
|---|---|
| CFI | 0.998 |
| TLI | 0.997 |
| RMSEA | 0.003 |
| SRMR | 0.012 |
The held-out fit is excellent, essentially perfect. That should prompt scrutiny rather than celebration. This survey was simulated from a clean three-factor structure, so the matching model recovers it unusually well even on validation data. Real survey responses usually contain cross-loadings, response styles, and correlated measurement error. Treat this result as a demonstration of what CFA measures, not as a promise of how real data will behave. After validating the structure, we refit it on all respondents to estimate one Avid, Social, and Food score per person using the Bartlett method.
cfa_score_fit <- lavaan::cfa(cfa_model, data = survey_sc,
std.lv = TRUE, estimator = "MLR")
fa_scores <- as.data.frame(
lavaan::lavPredict(cfa_score_fit, method = "Bartlett")
)
head(round(fa_scores, 2), 3)## Avid Social Food
## 1 -1.57 -1.76 -1.65
## 2 -3.50 -2.58 0.13
## 3 -2.84 -1.51 -2.005.3.3 Model-based segments with a Gaussian mixture
We now have three continuous scores per fan. The naive next move, which the previous edition of this chapter made, is to label each fan by whichever score is highest. That throws away most of the information: a fan who is high on everything and a fan who is barely above zero on everything both get filed under their single top score.
A better approach treats segmentation as a model. A Gaussian mixture model (GMM) assumes the fans are a blend of several overlapping clusters, each a cloud in the three-dimensional score space, and estimates both the clouds and each fan’s probability of belonging to each one. The mclust package (Fraley et al. 2025) fits it and, crucially, uses the BIC to choose how many clusters the data actually supports, rather than making us guess.
# mclust already computed the BIC for every k while fitting; reuse it.
bic_by_k <- data.frame(
k = as.integer(rownames(gmm$BIC)),
BIC = apply(gmm$BIC, 1, max, na.rm = TRUE)
)
ggplot(bic_by_k, aes(x = k, y = BIC)) +
geom_line(color = plot_palette[1]) +
geom_point(color = plot_palette[1], size = 2) +
geom_point(data = subset(bic_by_k, k == gmm$G), color = plot_palette[2], size = 4) +
labs(x = "Number of clusters (k)", y = "BIC (higher is better)",
title = "The BIC prefers four clusters") +
book_theme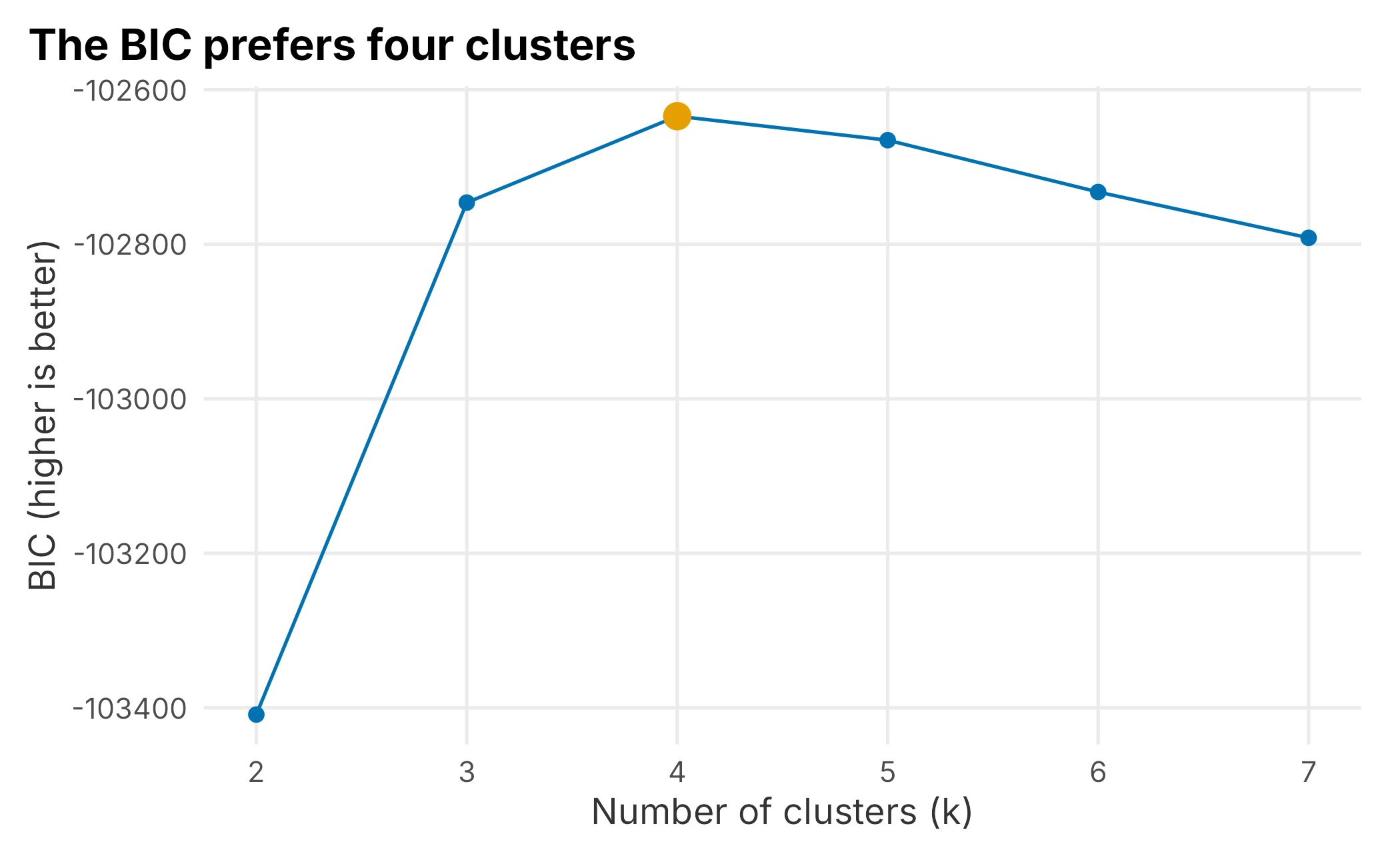
Figure 5.7: BIC across candidate cluster counts
The BIC peaks at 4 clusters, so mclust settles on a 4-segment solution (model type VVI). The segments are far from equal in size.
| segment | members | percent |
|---|---|---|
| 1 | 1005 | 10.1 |
| 2 | 5520 | 55.2 |
| 3 | 969 | 9.7 |
| 4 | 2506 | 25.1 |
To interpret the segments, we profile them by their average factor score. Because mclust numbers the segments arbitrarily, we label each one by the factor it is most extreme on. This is a small, data-driven rule that survives a re-run.
seg_profile <- fa_scores |>
dplyr::mutate(segment = gmm$classification) |>
dplyr::group_by(segment) |>
dplyr::summarise(dplyr::across(c(Avid, Social, Food), mean),
n = dplyr::n(), .groups = "drop")
z <- scale(as.matrix(seg_profile[, c("Avid", "Social", "Food")]))
seg_profile$label <- apply(z, 1, function(r) {
f <- c("Avid", "Social", "Food")[which.max(abs(r))]
paste(f, if (r[which.max(abs(r))] >= 0) "high" else "low")
})
seg_profile |>
tidyr::pivot_longer(c(Avid, Social, Food),
names_to = "factor", values_to = "score") |>
ggplot(aes(x = factor, y = label, fill = score)) +
geom_tile(color = "white") +
geom_text(aes(label = round(score, 1)), size = 3, color = "grey20") +
scale_fill_gradient2(low = plot_palette[2], mid = "#f2f2f2",
high = plot_palette[1], midpoint = 0) +
labs(x = "Factor", y = "Segment",
title = "Two segments are engagement tiers, not tastes") +
book_theme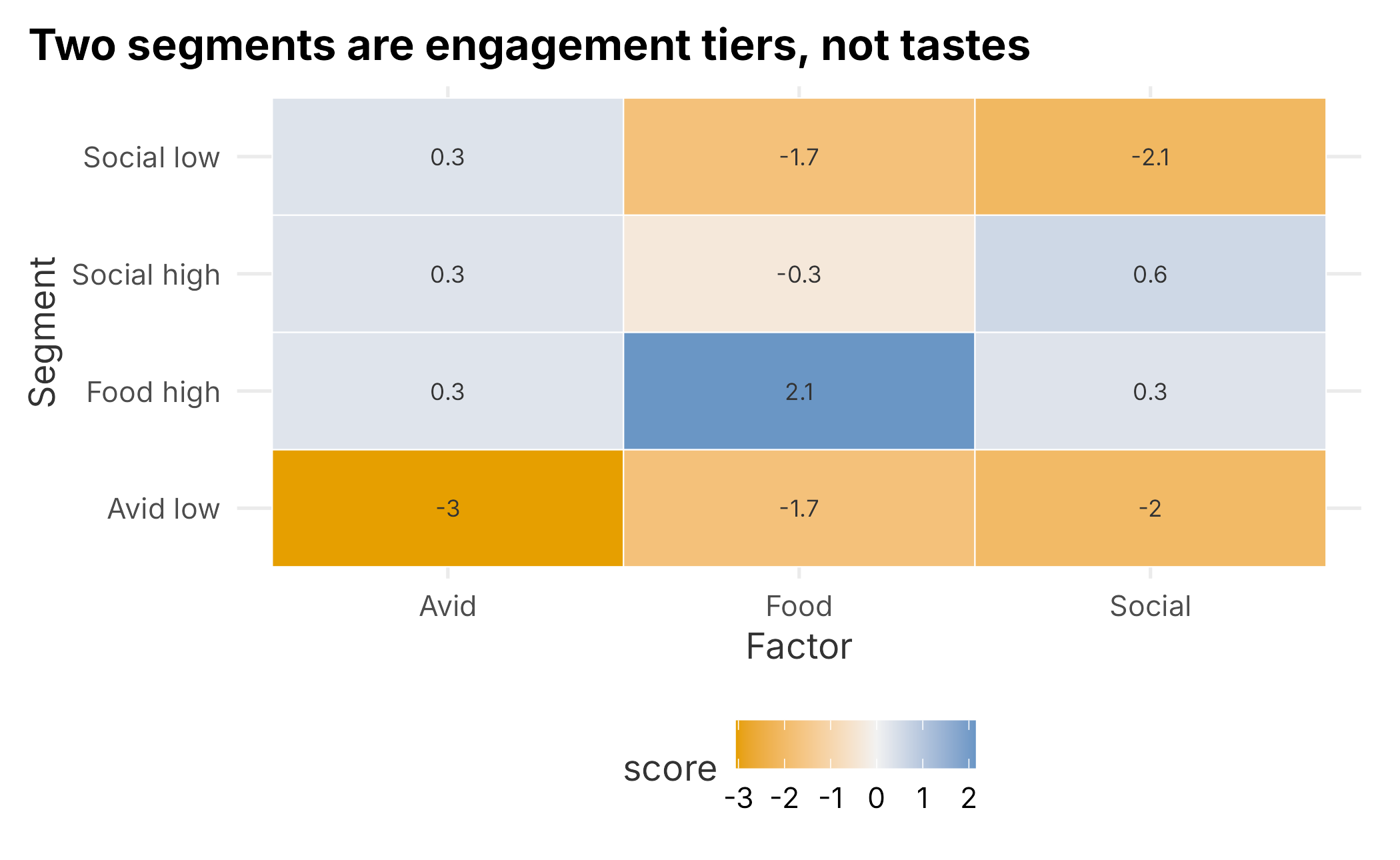
Figure 5.8: Behavioral segments by mean factor score
The profile is revealing, and a little deflating. Only two of the four segments look like the tastes we set out to find: a large Social-leaning mainstream (about 55% of fans) and a distinct Foodie group (about 25%) that scores far above everyone on food. The other two segments are essentially engagement tiers: one group is low on the social and food factors, and another is low on everything. The mixture did not carve the fan base into Avid-versus-Social-versus-Foodie; it mostly sorted fans by how much they want to do, not what. That is the difference between market structure and a behavioral segment, showing up in the output.
5.3.4 Are the segments real enough to act on?
Before we name these groups and hand them to marketing, we owe the organization two checks. This is the “first, do no harm” standard from the start of the chapter, made concrete.
First, how confident is each assignment? A GMM gives every fan a probability of belonging to each segment, so we can look at how crisp the assignments are.
max_posterior <- apply(gmm$z, 1, max)
data.frame(
avg_confidence = round(mean(max_posterior), 3),
share_below_80 = round(mean(max_posterior < 0.80), 3)
)## avg_confidence share_below_80
## 1 0.774 0.543More than half of fans have a top-segment probability below 0.80. In other words, the crisp four-box picture is an overstatement: a large share of fans sit in the fuzzy overlap between segments and could be assigned either way. Any profile that reports hard-segment averages as if every member truly belonged is quietly inflating the differences.
Second, would we get the same segments again? We resample the fans with replacement, refit the mixture, and measure how well the new segment labels agree with the original using the Adjusted Rand Index (ARI), where 1 is perfect agreement and 0 is chance. A dozen resamples is plenty to see the pattern and keeps the render quick.
set.seed(99)
base_class <- gmm$classification
ari <- replicate(12, {
idx <- sample(nrow(fa_scores), replace = TRUE)
fit <- mclust::Mclust(fa_scores[idx, ], G = gmm$G,
modelNames = gmm$modelName, verbose = FALSE)
pred <- predict(fit, fa_scores)$classification
mclust::adjustedRandIndex(pred, base_class)
})
data.frame(mean_ari = round(mean(ari), 2),
min_ari = round(min(ari), 2),
max_ari = round(max(ari), 2))## mean_ari min_ari max_ari
## 1 0.4 0.27 0.52The average ARI lands around 0.4, which is moderate rather than strong. The segments are not random noise, but they are not rock-solid either; resample the survey and the boundaries move.
Put the two findings together and you have a governance decision, not just a statistical one. Serious segmentation programs write down acceptance gates in advance. A segment scheme is only approved for activation if, say, every segment clears a minimum size, assignments are confident enough, and the scheme reproduces on resampled data. Judged against gates like those, this hard four-persona scheme is shaky: two “segments” are engagement tiers rather than tastes, over half of assignments are low-confidence, and stability is only moderate.
The constructive response is not to abandon the work. It is to activate on the continuous factor scores rather than the hard personas. The three Avid/Social/Food scores predict how a fan will behave more reliably than a box labeled “Segment 3,” because they keep the very information the hard assignment throws away. The named personas still earn their keep as a communication layer. It is far easier to brief a marketing team on “Foodies” than on a vector of factor scores, but the targeting logic underneath should run on the scores. Naming a segment is cheap; being able to reach it, and being right about it, is not.
5.3.5 Casting behavioral segments onto demographics
The behavioral scheme has one unavoidable weakness: you can only assign it to people who took the survey. A natural question is whether demographics could predict someone’s behavioral segment, extending the scheme to fans who never answered. Our survey was not tied to real customers, so we simulate the link by attaching each respondent to a random customer from the demographic segmentation. This is enough to show the mechanics while remaining honest that any relationship we see is manufactured.
set.seed(755)
fa_scores$behavior_raw <- factor(gmm$classification)
fa_scores$custID <- sample(demo_data_segments$custID, nrow(fa_scores))
combined <- demo_data_segments |>
dplyr::left_join(fa_scores, by = "custID") |>
na.omit()We give both schemes readable names. The behavioral names come from the segment profiles above. The demographic names summarize the strongest differences in the revised cross-tabs while avoiding claims the model no longer supports.
beh_names <- setNames(
ifelse(seg_profile$label == "Social high", "Social Mainstream",
ifelse(seg_profile$label == "Food high", "Foodies",
ifelse(seg_profile$label == "Social low", "No-frills Fans", "Low-involvement"))),
seg_profile$segment
)
combined$behavior_segment <- beh_names[as.character(combined$behavior_raw)]
combined$demo_segment <- dplyr::recode(as.character(combined$lcrClass),
"1" = "Young, Lower Income", "2" = "Older, Small Class",
"3" = "Older, Nearby", "4" = "Older, Distant",
"5" = "Younger, Male-Skewed")5.4 Psychographic segmentation
Psychographic schemes are the abstract, alliteratively named profiles you see everywhere, such as “Jets-fan Jeff” and “Tailgating Tina.” They combine behavioral and demographic schemes. We can build a simple version by crossing our two segmentations.
segment_grid <- combined |>
group_by(behavior_segment, demo_segment) |>
summarise(n = n(), .groups = "drop")
ggplot(segment_grid, aes(x = behavior_segment, y = demo_segment, fill = n)) +
geom_tile(color = "white") +
scale_fill_gradient("Count", low = "#f2f2f2", high = plot_palette[1],
labels = scales::comma) +
labs(x = "Behavioral segment", y = "Demographic segment",
title = "Crossing the two schemes yields psychographic cells") +
book_theme +
theme(axis.text.x = element_text(angle = 20, hjust = 1))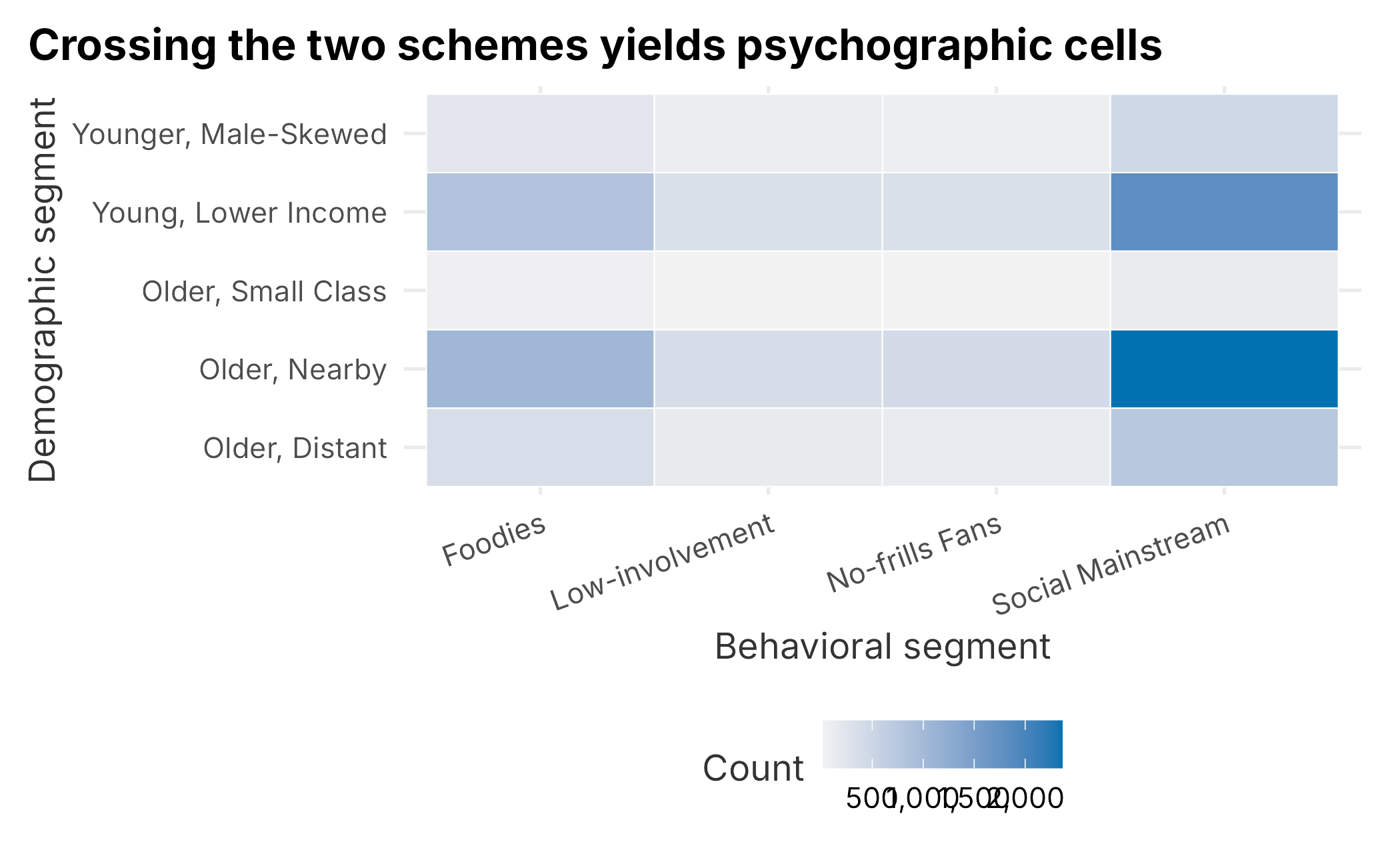
Figure 5.9: Behavioral segment by demographic segment
Every behavioral segment appears inside every demographic segment, which is the tell-tale sign that, in this contrived data, the two schemes are independent. To see it numerically, scale age and distance and average them within each cell.
combined$age_s <- as.numeric(scale(as.numeric(combined$age)))
combined$distance_s <- as.numeric(scale(as.numeric(combined$distance)))
segment_profile <- combined |>
group_by(behavior_segment, demo_segment) |>
summarise(age = mean(age_s), distance = mean(distance_s), .groups = "drop")
ggplot(segment_profile,
aes(x = age, y = distance, color = behavior_segment, shape = demo_segment)) +
geom_point(size = 3) +
scale_color_manual("Behavioral", values = plot_palette) +
scale_shape_manual("Demographic", values = c(15, 16, 17, 18, 3)) +
geom_hline(yintercept = median(segment_profile$distance), linetype = 2, color = "grey60") +
geom_vline(xintercept = median(segment_profile$age), linetype = 2, color = "grey60") +
labs(x = "Scaled average age", y = "Scaled average distance",
title = "Demographic segments separate on age; behavioral segments do not") +
book_theme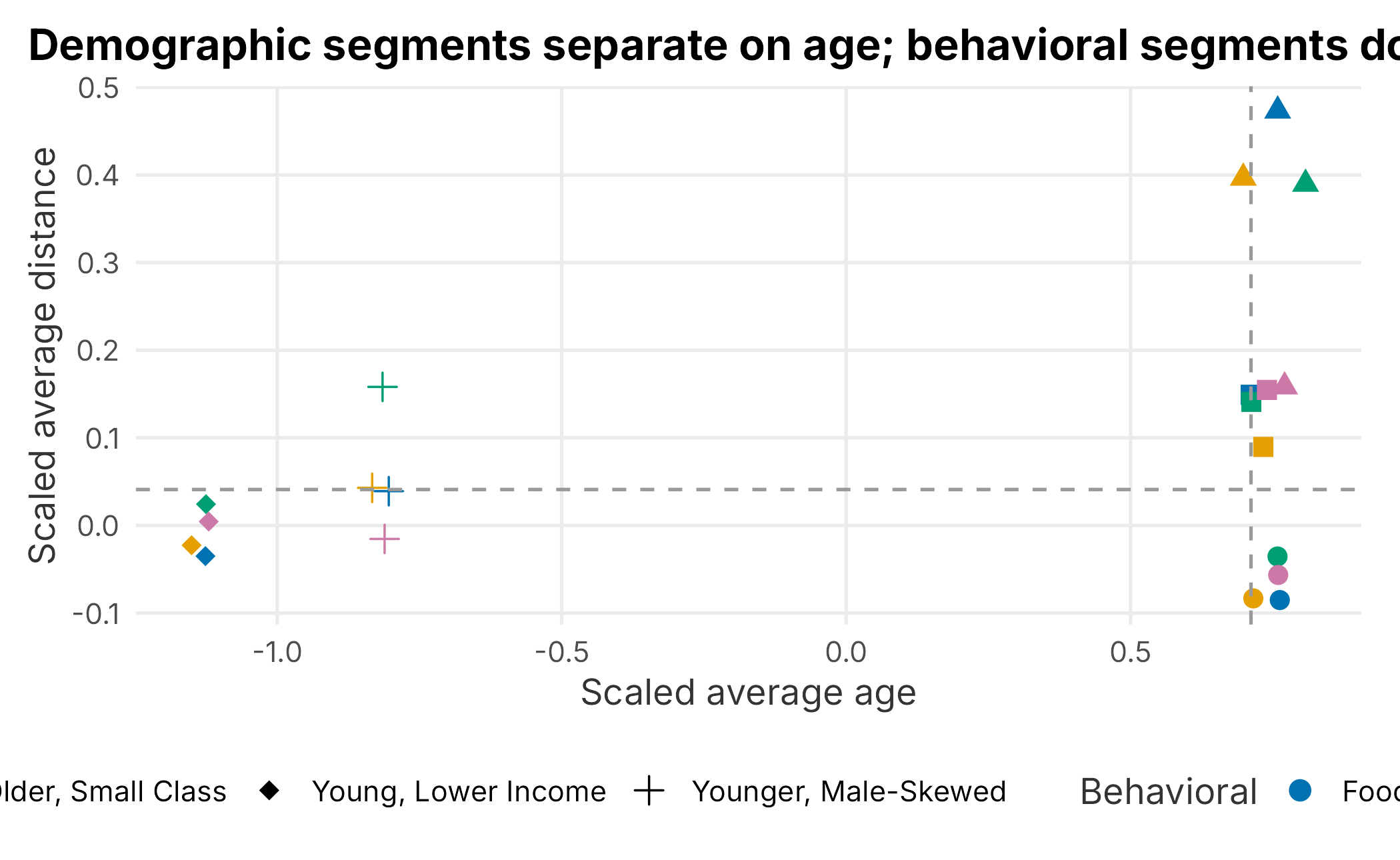
Figure 5.10: Segments by scaled age and distance
The picture is clear once you know what to look for. The points separate left-to-right by demographic segment (the shapes) and barely at all by behavioral segment (the colors). The older nearby and older distant groups separate most clearly on the distance axis, while the two younger groups sit apart on the age axis. The behavioral archetypes carry no age or distance signal here, exactly as expected because they were layered on at random. With real survey data tied to real customers, this is where genuine psychographic profiles would start to emerge.
We are, once again, only getting started. A full analysis would be more exhausting but no more complicated. It repeats the same steps. The point of the example is how much careful, tedious work sits between raw data and a usable segment.
5.5 Other segmentation methods
There are hundreds of ways to segment data. As a rule, start with the simplest scheme that could work, even a single rule, and add complexity only when it earns its keep. Other common tools include:
- K-means clustering for well-scaled continuous features
- K-medoids with Gower distance for mixed numeric and categorical data
- K-prototypes for larger mixed-type data sets
- Density-based clustering for irregularly shaped groups and noise
- Simple rule-based schemes
No single approach is best. In The Signal and the Noise, Nate Silver contrasts the hedgehog, who knows one big thing, with the fox, who knows many small things (Silver 2012). For this kind of work, be the fox: combine practical knowledge with an analytical process. A purely numerical approach rarely gives the best answer.
5.6 Key concepts and chapter summary
Segmentation is part art, part science, and mostly patience. We worked through a fairly complete example and hit the high points:
- Exploring and preparing data for a demographic segmentation, including missing-data imputation
- A hierarchical clustering approach and a latent class analysis on demographics
- A benefits-sought approach built as a three-step measurement pipeline: exploratory factor analysis, a confirmatory factor analysis, and a Gaussian mixture model
- Checking whether the resulting segments are stable and confident enough to act on
- Combining the schemes into psychographic profiles
A few lessons are worth keeping:
- The goal is to find exploitable differences, not just market structure. Groups that differ only in how much they engage, like the engagement tiers our mixture surfaced, are market structure, not segments.
- Demographic segmentation is the easiest place to start and often the least useful. It is discoverable, which is its main virtue.
- Preparing the data, especially handling missing values, will take most of your time and bears heavily on the result. There is rarely one right method; document your judgment calls.
- Let the data choose the number of factors and clusters. Parallel analysis and the BIC guard against the ever-present temptation to extract more structure than the data supports.
- Exploratory and confirmatory factor analysis answer different questions. EFA finds the structure; CFA tests a structure you specify. Good CFA fit on real data is hard-won. Be suspicious when it comes easily.
- A model-based mixture beats labeling fans by their single top score, because it keeps the probability that a fan belongs to each group. Most fans are not crisply one thing.
- Validate before you deploy. Check segment sizes, assignment confidence, and stability against resampling. When hard personas are fragile, as ours were, activate on the continuous factor scores and keep the personas as a communication layer.
Above all, hold the standard we started with: it is fine to find nothing, and far better than deploying a segment that is not real. Chapter 6 turns to pricing and forecasting, where the cost of a confident wrong answer shows up directly on the revenue line.